How can I help you?
{textContent ? {textContent} : null}
{imageParts.length > 0 ? (
);
} else {
return (
{imageParts.map((part, idx: number) => {
const { base64Only, mediaType } =
parseImagePartToDataUrl(part);
if (!base64Only) {
return null;
}
return (
) : null}
{isLastMessage &&
(status === "submitted" || status === "streaming") && (
{p.text}
;
}
return null;
})}
{status === "streaming" ? (
stop()} variant="ghost">
Stop
) : null}
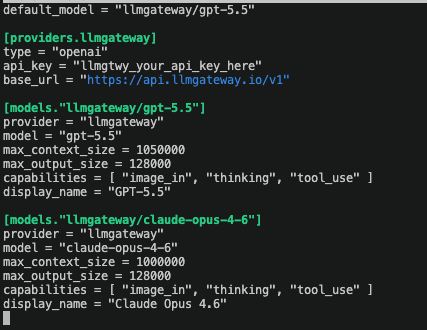
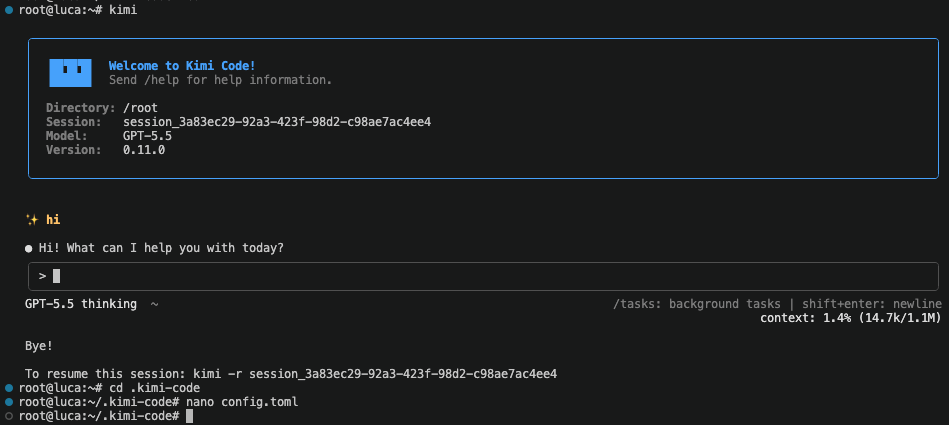
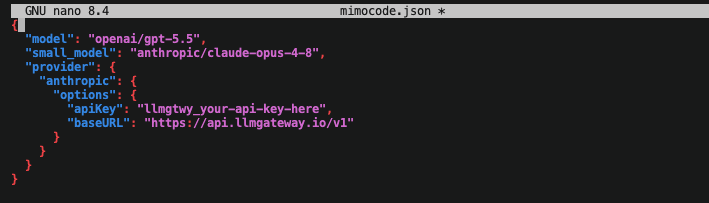
不同于 OpenRouter,我们提供:
- 完整的自托管能力,让你可以完全掌控自己的基础设施
- 更深入的分析能力,帮助你理解模型用量和性能表现
- 使用自有 provider key 时不收取额外费用,最大化成本效率
- 面向企业部署的更高灵活性和自定义能力
How can I help you?
{textContent ? {textContent} : null}
{imageParts.length > 0 ? (
);
} else {
return (
{imageParts.map((part, idx: number) => {
const { base64Only, mediaType } =
parseImagePartToDataUrl(part);
if (!base64Only) {
return null;
}
return (
) : null}
{isLastMessage &&
(status === "submitted" || status === "streaming") && (
{p.text}
;
}
return null;
})}
{status === "streaming" ? (
stop()} variant="ghost">
Stop
) : null}